



1. Crear cuenta
Registra una cuenta de Cloudbypass API: Registrarse ahora
Registra una cuenta de Cloudbypass Proxy: Registrarse ahora
Las cuentas son compartidas. Registra una sola y, en 30 días, entra al panel y haz clic en “🎁 Prueba” para recibir créditos y tráfico de prueba.
2. Generador de código
Introduce tu URL en el generador de código y prueba si el flujo de verificación de Cloudflare se gestiona correctamente.
La versión V1 incluye un pool de IP dinámicas y no requiere proxy si el acceso es correcto.
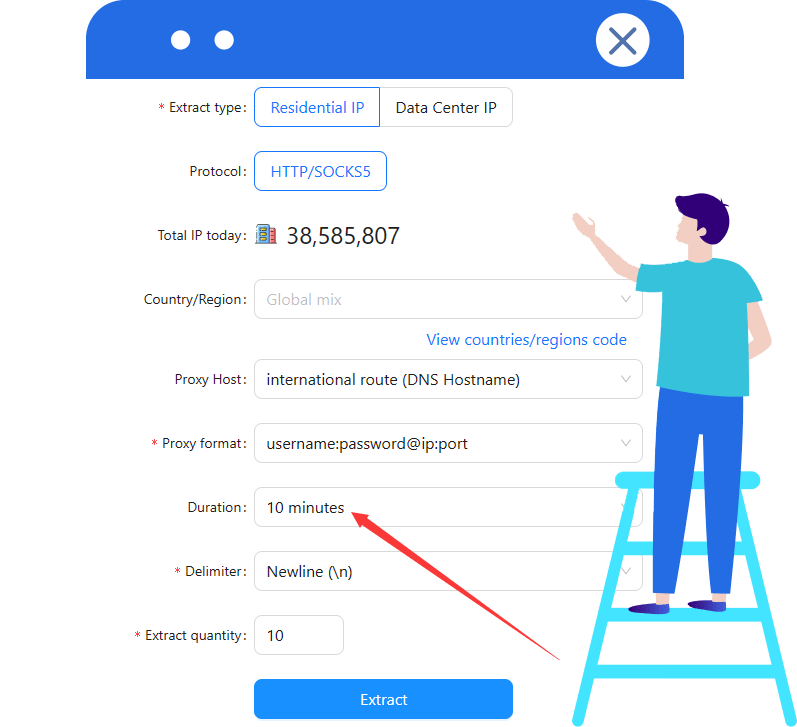
La versión V2 requiere IP fija o con validez temporal; para IP dinámica de Cloudbypass, configura ≥10 minutos. (ver imagen)
Para soporte técnico, revisa la documentación de la API o contacta al soporte.
3. Integrar Cloudbypass API
Integra el código de Cloudbypass API en tu módulo, ajusta parámetros y finaliza las pruebas.
4. Elegir plan
Selecciona el plan según tu uso: Ver precios
Para gestionar el JS Challenge de Cloudflare: 【Plan de créditos】
Para tráfico de proxy IP: 【Proxies de centro de datos dinámicos o residenciales dinámicos】
Gestionar Cloudflare consume créditos. A veces requiere proxy IP como apoyo; solo usar proxy IP no gestiona Cloudflare.