


1.アカウント登録
Cloudbypass API アカウント登録:新規登録
Cloudbypass Proxy アカウント登録:新規登録
アカウントは共通です。どちらか一方の登録で利用できます。登録後 30 日以内に管理画面へログインし、「 🎁 トライアル 」ボタンからクレジット/トラフィックのスターターパックを受け取ってください。
2.コードジェネレーター
アクセス先 URL を コードジェネレーター に入力し、Cloudflare challenge の検証フローが処理できているか確認します。
V1:動的 IP プール内蔵。アクセスできる場合はプロキシ設定は不要。
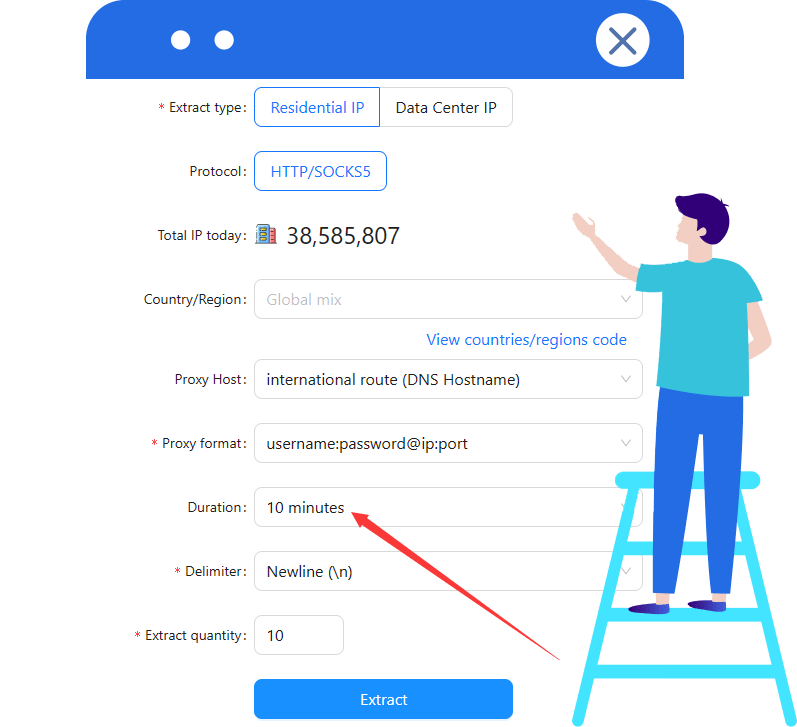
V2:固定 IP または期限付き IP の設定が必要。Cloudbypass の動的 IP を使う場合は有効期限を 10 分以上に設定してください。(図参照)
技術的な確認は API ドキュメント、または サポート窓口 へ。
3.Cloudbypass API を組み込み
生成したコードを既存のモジュールに組み込み、最終デバッグ後に運用します。
4.プラン購入
要件に合わせてプランを選択:料金を見る
Cloudflare challenge の処理は:【クレジットプラン】
プロキシのトラフィックは:【動的 データセンター IP/動的 レジデンシャル IP】
Cloudflare challenge の処理にはクレジットを消費します。ケースによってはプロキシ併用が必要ですが、プロキシのみでは Cloudflare challenge を処理できません。