看起来简单的设计,复杂性通常是从什么时候开始堆积的?
很多系统在最初阶段都会被评价为“设计很简单”:逻辑直观、代码不多、问题也好排查。但随着功能增加、运行时间拉长、…

绕过多种验证机制:支持突破 Cloudflare 的 JavaScript Challenge(5秒盾)、Turnstile CAPTCHA、Imperva Incapsula 等验证机制。
全球动态代理支持:提供高速 HTTP/Socks5 API 提取 IP 代理,涵盖全球动态住宅 IP 和机房代理 IP,确保访问的稳定性和匿名性。
浏览器行为模拟:可自定义设置代理、Referer、User-Agent、Headless 状态等浏览器指纹及设备特征,模拟真实用户行为,降低被识别的风险。
多语言支持:适用于cURL、Python(SDK)、Go(SDK)、Nodejs(SDK)、Java 等多种编程语言,方便集成到现有的爬虫脚本或数据采集项目中。
极速接入体验:协议请求直接返回网页源码,跨平台兼容、并发处理能力强,接入快速且节省流量,助力项目高效获取所需数据。
注册领取试用 获取穿云API 代码生成器
访问 https://opensea.io/path/to/target?a=4,以下是Curl请求示例:
# Use curl to request https://opensea.io/category/memberships
# curl -X GET "https://opensea.io/category/memberships"
# 使用 穿云API 请求示例
# Use Cloudbyapss API to request
curl -X GET "https://api.cloudbypass.com/category/memberships" ^
-H "x-cb-apikey: YOUR_API_KEY" ^
-H "x-cb-host: opensea.io" -k
# 使用 穿云Proxy 请求示例
# Use Cloudbyapss Proxy to request
curl -X GET "https://opensea.io/category/memberships" -x "http://YOUR_API_KEY:@proxy.cloudbypass.com:1087" -k
详细文档
访问 https://opensea.io/path/to/target?a=4,以下是Python请求示例:
// Use python to request https://opensea.io/category/memberships
import requests
"""
# 修改前的代码示例
# original code
url = "https://opensea.io/category/memberships"
response = requests.request("GET", url)
print(response.text)
print(response.status_code,response.reason)
# (403, 'Forbidden')
"""
# 使用 穿云API 请求示例
# Use Cloudbyapss API to request
url = "https://api.cloudbypass.com/category/memberships"
headers = {
'x-cb-apikey': 'YOUR_API_KEY',
'x-cb-host': 'opensea.io',
}
response = requests.request("GET", url, headers=headers)
print(response.text)
// Use python to request https://opensea.io/category/memberships
import requests
"""
# 修改前的代码示例
# original code
url = "https://opensea.io/category/memberships"
response = requests.request("GET", url)
print(response.text)
print(response.status_code,response.reason)
# (403, 'Forbidden')
"""
# 使用 穿云API 请求示例
# Use Cloudbyapss API to request
url = "https://api.cloudbypass.com/category/memberships"
headers = {
'x-cb-apikey': 'YOUR_API_KEY',
'x-cb-host': 'opensea.io',
}
response = requests.request("GET", url, headers=headers)
print(response.text)
详细文档
访问 https://opensea.io/category/memberships,以下是Go请求示例:
// # Go Modules
// require github.com/go-resty/resty/v2 v2.7.0
package main
import (
"fmt"
"github.com/go-resty/resty/v2"
)
func main() {
client := resty.New()
client.Header.Add("X-Cb-Apikey", "/* APIKEY */")
client.Header.Add("X-Cb-Host", "opensea.io")
resp, err := client.R().Get("https://api.cloudbypass.com/category/memberships")
if err != nil {
fmt.Println(err)
return
}
fmt.Println(resp.StatusCode(), resp.Header().Get("X-Cb-Status"))
fmt.Println(resp.String())
}
详细文档
访问 https://opensea.io/path/to/target?a=4,以下是Nodejs请求示例:
// Use javascript to request https://opensea.io/category/memberships
const axios = require('axios');
/*
// 修改前的代码示例
// original code
const url = "https://opensea.io/category/memberships";
axios.get(url, {})
.then(response => console.log(response.data))
.catch(error => console.error(error));
*/
// 使用 穿云API 请求示例
// Use Cloudbyapss API to request
const url = "https://api.cloudbypass.com/path/to/target?a=4";
const headers = {
'x-cb-apikey': 'YOUR_API_KEY',
'x-cb-host': 'www.example.com',
};
axios.get(url, {}, {headers: headers})
.then(response => console.log(response.data))
.catch(error => console.error(error));
# Use javascript to request https://opensea.io/category/memberships
const axios = require('axios');
// 使用 穿云Proxy 请求示例
// Use Cloudbyapss Proxy to request
const url = "https://opensea.io/category/memberships";
const config = {
proxy: {
host: 'proxy.cloudbypass.com',
port: 1087,
auth: {
username: 'YOUR_API_KEY',
password: ''
// Use a custom proxy
// password: 'proxy=http:CUSTOM_PROXY:8080'
}
}
};
axios.get(url, config)
.then(response => console.log(response.data))
.catch(error => console.error(error));
详细文档
访问 https://opensea.io/path/to/target?a=4,以下是Java请求示例:
// Use java to request https://opensea.io/category/memberships
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
public class Main {
public static void main(String[] args) throws Exception {
/*
// 修改前的代码示例
// original code
String url = "https://opensea.io/category/memberships";
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.GET(HttpRequest.BodyPublishers.noBody())
.build();
HttpResponse response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
*/
// 使用 穿云API 请求示例
// Use Cloudbyapss API to request
String url = "https://api.cloudbypass.com/category/memberships";
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("x-cb-apikey", "YOUR_API_KEY")
.header("x-cb-host", "opensea.io")
.GET(HttpRequest.BodyPublishers.noBody())
.build();
// 使用 穿云Proxy 请求示例
// Use Cloudbyapss Proxy to request
String url = "https://opensea.io/category/memberships";
HttpClient client = HttpClient.newBuilder()
.proxy(HttpClient
.ProxySelector
// Use a custom proxy
//.of(URI.create("http://YOUR_API_KEY:proxy=http:CUSTOM_PROXY:[email protected]:1087")))
.of(URI.create("http://YOUR_API_KEY:@proxy.cloudbypass.com:1087")))
.build();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.GET()
.build();
HttpResponse response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
}
}
详细文档
注册穿云API账号,点击 立即注册
注册穿云代理账号,点击 立即注册
穿云账号是互通的,只要注册其一即可,注册后30天内登录后台,点击" 🎁 试用活动 "按钮,领取积分和流量的新手试用礼包。
将您的请求地址输入到:代码生成器 中,测试是否完成绕过Cloudflare验证。
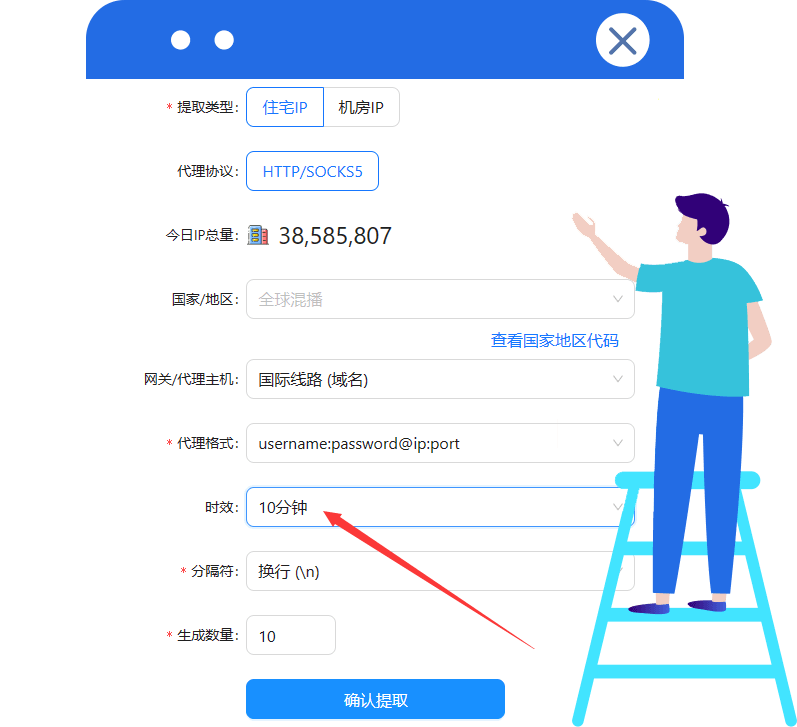
V1版本自带动态IP池,如可访问,不需要配置IP代理;
V2版本必须配置固定IP或时效IP,如穿云动态IP需设置10分钟以上时效。(如图)
将穿云API代码集成到您自己的代码功能模块中,完成最终调试并使用。
最后根据需求选择套餐购买:查看价格
绕过Cloudflare5秒盾验证需购买:【积分套餐】
IP代理流量就购买:【动态机房IP或动态住宅IP】
绕过Cloudflare需要消耗积分,有时需IP代理辅助完成,但只用IP代理是不能绕过Cloudflare的。

穿云API 提供面向 Cloudflare 安全防护场景的专业访问解决方案,兼容 JavaScript Challenge(五秒盾)、Turnstile CAPTCHA 等常见人机验证机制。 即使在高并发场景下发送大规模请求,也能保持稳定访问成功率,广泛适用于数据采集、自动化访问与系统集成。
穿云API 提供 HTTP API 与代理(Proxy)两种灵活请求模式,开发者无需重构复杂逻辑, 即可在现有项目中快速接入 Cloudflare 访问解决方案,显著降低开发与维护成本。


穿云API 作为企业级 HTTP 请求与代理访问工具,专注于 Cloudflare 等安全防护环境下的稳定访问能力。 通过真实浏览器环境模拟与访问参数控制,帮助开发者在复杂风控场景中保持请求成功率与数据一致性。
穿云API 的代理访问模式支持多平台部署与高并发请求处理, 可在保证访问成功率的同时有效降低流量与计算资源消耗,适用于长期稳定运行的自动化系统。








依托穿云API,可在复杂网络环境中实现稳定的数据获取。支持代理切换、浏览器指纹与 JS 验证绕过,确保采集过程顺畅无阻。
提供大规模代理资源,保障视频与图片内容的稳定抓取。结合穿云API支持多种应用场景,涵盖机器学习训练、内容监控等需求。
通过穿云API稳定获取商品信息、价格、库存及无论数据。支持跨境平台的数据分析与优化,助力电商运营提升效率。
可采集航班、酒店、票务与签证等全链路数据。结合防护机制,保障数据获取稳定可靠,为行业分析与预测提供支持。
支持抓取各大电商平台的优惠信息,结合智能代理机制,帮助商家及时掌握促销动态,提升用户体验与竞争力。
实现对新闻与网络小说的持续采集,保障内容更新稳定。支持多维度处理与结构化分析,确保数据真实、完整。

成功请求1次API消耗1次积分,请求失败不消耗积分。
V1版本 成功请求1次消耗1个积分;
V2版本 成功请求1次消耗3个积分(请求1次API消耗1个积分,V2通过JS轮询会多消耗2个积分,会话时长为10分钟,在不更换代理和part参数的情况下可以保持会话状态,避免不必要的验证,也就是说第一次请求后10分钟内,继续请求不额外收费了。)
穿云API积分在有效期内没用完就会清空;
再充值的是独立计算的,和之前购买的没关系,但会优先消耗最早购买的积分。
穿云API提供服务的模式是你提交http请求,API替你发送该请求,这个过程能让你的http请求更难识别出来是机器人,只会尽可能绕过Cloudflare验证码,让Cloudflare验证码不出现,直接访问目标网址,并不是自动去点击Cloudflare验证码。
V2版本能过js轮询(能渲染JS);
目前V2版本没有默认代理,需要再购买穿云代理IP,V1版本自带动态代理
会话分区用来区分管理cloudflare Cookie的,通过验证后会话生效。生效后代理IP、指纹等将持续10分钟无法更改,这是为了保证在会话期间内不会触发新的验证。至于账号会话需要自行管理。
从0-999,用户最多可以拥有1000个会话分区。第一次请求成功后会话分区将会锁定代理IP,可以通过修改会话分区值提交其它代理IP。会话锁定时长为十分钟,成功请求将刷新时长。
目前我们所有套餐的最大并发请求数是30次/s。
INSUFFICIENT_BALANCE 这个错误是你没有穿云API积分了。
你可以在穿云API后台购买:https://console.cloudbypass.com/#/api/login,或 联系客服:领取测试积分。
报错信息:
"code": "CHALLENGE_LOCK_OCCUPIED"
"message": "The current part is being challenged, please wait for the lock to be released."
错误说明:
出现 CHALLENGE_LOCK_OCCUPIED 说明代码可能存在以下问题:
同一 part 被多个线程同时使用。
多个用户使用同一账号并操作相同 part。
上一个请求占用了验证锁,可能因超时或人为中断尚未完成。
解决方案:
等待锁释放,稍后再尝试请求。
更换 part,可选范围为 0~999。
解决方案:
1、提取IP时设置10分钟时效。
2、换个国家地区的IP。(多提取点不同国家的IP轮询使用,只用同一个国家地区的IP容易被限制)
这种情况大概率是需要配置代理IP了,选择API模式和代理模式其中一种来使用我们的服务,国内用户推荐使用API模式,目前只支持http协议的代理IP。
目前不支持selenium和Puppeteer的浏览器自动化,因为没使用到浏览器,只是模拟浏览器请求。
我们没有包月套餐,我们的定价计划是按流量包计费的,不限制时效;您可以根据自身需求购买流量包,用多少买多少,永不过期。
穿云代理支持支付宝,USDT等付款方式。
动态IP代理使用量=上传+下载数据。
请使用我们提供的 http://ipinfo.cloudbypass.com 查询。
穿云代理IP提供两种代理网络:动态住宅代理IP和动态机房IP(数据中心代理)。
在穿云代理,您可以一站式购买所需的各种代理形式。
穿云代理目前支持http以及Socks5代理协议。
我们的定价模式主要是基于流量包形式的。对于动态住宅IP和动态机房IP,我们都是按流量包的套餐模式,无限制时效。您可注册后申请免费试用,以评估我们的解决方案并确定您购买的流量包。
很遗憾,我们的代理无法中国大陆IP环境下直连。
但是您可以部署一个境外网络环境(如香港的服务器),在境外网络中尽情使用代理。
在电脑端您可以部署全局NPV加速器辅助使用;
在手机端您可以部署一个软路由,手机通过连接路由器WIFI网络处于境外环境下;
如果您没有搭建境外网络环境的能力,请停止购买,我们不为直连的中国用户提供退款。

穿云API积分消耗简明规则:成功请求1次消耗1积分,V2版本消耗3积分。积分有效期1个月内清空,再充值独立计算。V2版本支持JS轮询,需购买时效代理IP。最大并发请求数30次/秒。403或Access Denied问题可能需配置代理IP。不支持selenium或Puppeteer,可结合指纹浏览器和采集器使用。
查看更多
穿云海外IP代理按流量包计费,永不过期。支持支付宝、USDT等支付方式。流量包使用量为上传+下载数据。提供动态住宅和机房IP,支持http和Socks5代理协议。注册后可申请免费试用。中国用户需在境外环境使用,无法直连中国大陆IP。我们仅提供海外代理IP,建议在境外服务器部署全局NPV加速器或软路由。
查看更多
穿云API绕过Cloudflare,确保无阻网页数据采集。提供HTTP API和全球动态IP代理服务,支持设置Referer、UA等浏览器指纹,提供更灵活的控制权。穿云代理IP服务设置涵盖常见问题、IP提取教程、指纹浏览器、电脑浏览器和手机移动端。详细指南包括多款浏览器和平台的穿云代理IP配置。
查看更多
“穿云API极大地提升了我的数据采集和网页抓取效率。尤其是在处理需要绕过Cloudflare五秒盾和人机验证的网站时,它表现非常稳定可靠。接口设计简洁易懂,让我几乎零学习成本即可上手,大幅减少了开发与调试的时间。对于像我这样需要长期处理海量数据的科研工作者来说,穿云API无疑是一款能够节省精力并保证数据采集质量的高效反爬虫工具,强烈推荐给所有从事自动化爬虫和大规模数据挖掘的开发者!”
“我从事网络爬虫开发多年,遇到最大的问题往往是Cloudflare的验证码和防护机制。自从使用穿云API之后,这些困扰迎刃而解。它能稳定、快速地绕过Cloudflare验证,确保爬虫在长时间运行中依然高效稳定,真正实现了‘无感采集’。现在,我能够更专注于业务逻辑和数据分析,而不是花时间去处理烦人的反爬机制。穿云API已经成为我项目中不可或缺的一部分!”
“作为自由职业者,我经常需要为不同客户进行网页数据采集和内容抓取。过去,遇到Cloudflare五秒盾和复杂的JS挑战,总让我感到头疼。但自从接触穿云API后,一切都变得简单顺畅。它能精准识别并自动处理各种验证,大幅减少了我的人工干预,让我能够快速交付高质量的数据。穿云API不仅功能强大,而且使用体验非常流畅,是一款值得长期信赖的专业数据采集API。”
“在市场研究中,获取全面且及时的数据至关重要。然而,许多网站都有反爬虫机制,尤其是Cloudflare的403错误和验证码拦截,这曾经让我十分头疼。穿云API彻底解决了这一问题,它帮助我稳定地采集目标网页数据,让我无需担心访问受阻。它的优势在于兼具高效性和可靠性,让我能够快速完成分析报告,提升了团队的整体效率。对于任何需要大量数据支撑的分析工作,我都强烈推荐穿云API!”
“我一直在寻找一款能稳定应对Cloudflare防护的工具,而穿云API正好满足了我的需求。它可以轻松绕过Cloudflare五秒盾和人机验证,而且接口文档详细清晰,开发者上手毫无压力。在我的多个爬虫项目中,穿云API大幅提升了采集的成功率和稳定性,再也不用被验证码中断流程。对于程序员来说,它不仅仅是一个工具,更像是一个可靠的伙伴,真正提高了工作效率。”
“起初我是通过朋友推荐才了解到穿云API的,坦白说一开始我对它的实际效果还有些怀疑。但在我的创业项目中亲身尝试后,我发现它确实能稳定绕过Cloudflare的各种人机验证与反爬虫挑战,让我的数据采集流程变得顺畅高效。对创业团队而言,时间和资源都十分宝贵,而穿云API正好解决了最棘手的技术难题,为我的业务增长带来了极大的助力。可以说,它是我项目发展的秘密武器。”





