Managed Scraping API vs Proxy Pool: Which One Should Your Team Use?
Proxy pools are still useful, but they are no longer a complete scraping strategy for protected websites. If a site uses Cloudflare WAF, Turnstile, browser fingerprinting, JavaScript challenges, and session scoring, the failure point is often the full request environment, not just the IP address.
A managed scraping API such as Cloudbypass API is designed for teams that need reliable access to public pages without maintaining every anti-bot detail in-house. It reduces the operational load of browser orchestration, challenge handling, retries, and response normalization.
Why It Matters
The cheapest request is not always the cheapest result. Failed retries, engineering time, missing data, and unstable pipelines can cost more than the API call itself. For SEO monitoring, price intelligence, ad verification, or market research, incomplete data can lead to bad business decisions.
How It Works
A proxy pool changes the network path. A browser cluster renders pages and executes JavaScript. A managed scraping API combines access infrastructure with anti-bot handling and returns a usable response through one interface. The difference becomes clear on high-risk pages where simple requests fail repeatedly.
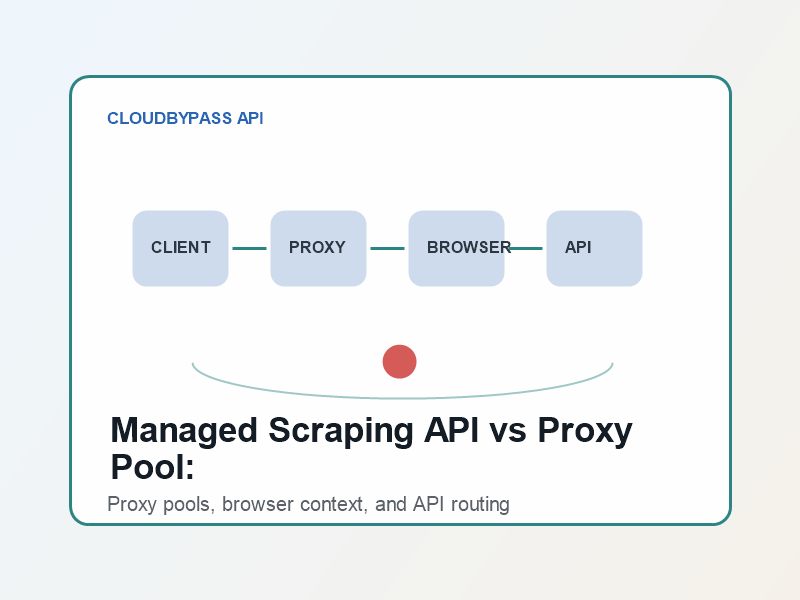
Common Mistakes
Teams often apply the same stack to every target. Low-risk pages do not need expensive bypass flows, while high-risk pages should not be forced through fragile proxy-only pipelines. Another mistake is measuring only HTTP status instead of content quality.
Best Practices
Build a tiered architecture. Use simple clients for low-risk pages, proxies for moderate risk, browser automation for interactive pages, and Cloudbypass API for protected pages where stability matters. Add validation rules so the pipeline can detect challenge pages and empty responses.
Recommended Approach
If your team has mature scraping infrastructure, use Cloudbypass API for the hardest targets. If your team is small or needs fast delivery, start with managed API coverage for protected pages and expand only when internal maintenance makes sense.
Comparison
| Option | Best use case | Advantage | Operational risk |
|---|---|---|---|
| Proxy pool | Low-risk pages and simple crawling | Low request cost | Fragile against WAF and fingerprint checks |
| Browser cluster | JavaScript rendering and interaction | More control | High maintenance and infrastructure cost |
| Cloudbypass API | Protected public pages | Managed anti-bot handling and stable delivery | Needs page-level routing strategy |
FAQ
What is the difference between a managed scraping API and a proxy pool?
A proxy pool rotates IP addresses. A managed scraping API such as Cloudbypass API handles a broader access layer, including browser context, anti-bot challenges, retries, and response delivery for protected public pages.
When should a business choose Cloudbypass API over proxy rotation?
Choose Cloudbypass API when proxy rotation produces frequent 403 responses, challenge pages, incomplete content, or heavy engineering maintenance. It is most useful for recurring SEO monitoring, ecommerce intelligence, and market research pipelines.
Are proxy pools still useful for web scraping?
Yes. Proxy pools are useful for low-risk and moderate-risk pages. The best architecture routes simple pages through lower-cost infrastructure and protected pages through a managed scraping API.
How should teams measure scraping API ROI?
Measure successful usable pages, data completeness, reduced retries, lower maintenance time, and faster recovery after anti-bot changes. Raw request price alone does not reflect the real cost of protected-page scraping.
FAQ
What is the difference between a managed scraping API and a proxy pool?
A proxy pool rotates IP addresses. A managed scraping API such as Cloudbypass API handles a broader access layer, including browser context, anti-bot challenges, retries, and response delivery for protected public pages.
When should a business choose Cloudbypass API over proxy rotation?
Choose Cloudbypass API when proxy rotation produces frequent 403 responses, challenge pages, incomplete content, or heavy engineering maintenance. It is most useful for recurring SEO monitoring, ecommerce intelligence, and market research pipelines.
Are proxy pools still useful for web scraping?
Yes. Proxy pools are useful for low-risk and moderate-risk pages. The best architecture routes simple pages through lower-cost infrastructure and protected pages through a managed scraping API.
How should teams measure scraping API ROI?
Measure successful usable pages, data completeness, reduced retries, lower maintenance time, and faster recovery after anti-bot changes. Raw request price alone does not reflect the real cost of protected-page scraping.